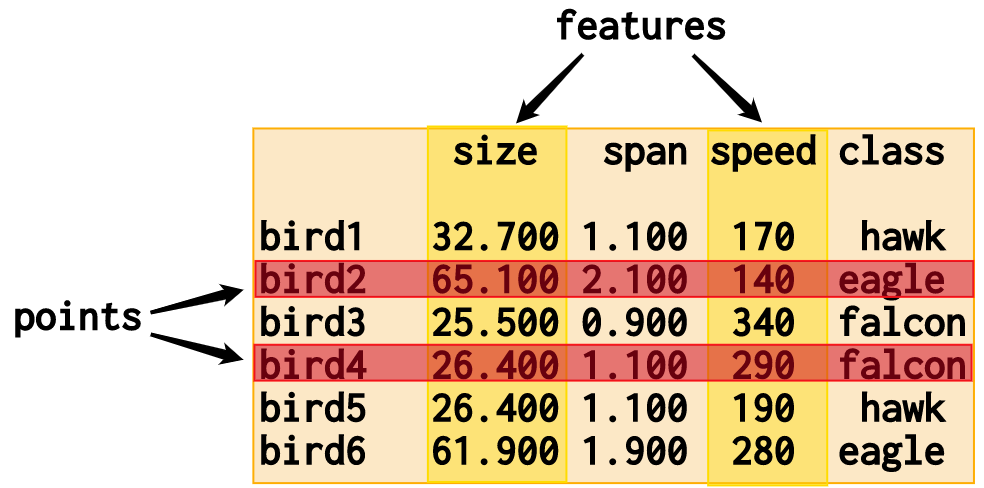
Visualization of a Nimble data object:
Nimble is built on top of Python’s most popular data science and machine learning libraries to provide a single, easy to use, API for any data science job.
Visualization of a Nimble data object:
Nimble has 4 data types that share the same API.
Each use a different backend to optimize the operations based on the type of data in the object. Choosing the type that best matches the data will support more efficient operations. By default, Nimble will attempt to automatically detect the best type.
| Type | Data | Backend |
| List | any data | Python list |
| Matrix | all the same type | NumPy array |
| DataFrame | each column has 1 type | Pandas DataFrame |
| Sparse | mostly missing or 0 | SciPy coo_matrix |
A Nimble data object acts as the container of all individual elements of your data. But for manipulating that data, Nimble defines an API that abstracts away from the structure of how it is recorded to emphasize the meaning of how elements inter-relate.
Instead of operating on rows and columns (as with a spreadsheet or matrix), Nimble defines methods over points and features. This aligns with the goal of machine learning ready data, where each point should be a single observation of unique variables and each feature should define a single variable that has been recorded across observations. Nimble's API provides tools to tidy data towards that goal while behaving in a way that respects the observational meaning of data.
The methods of the Nimble data object control operations that apply to the entire object or the elements. The points and features properties of the object have additional methods for operations that apply along that axis of the data object.
bird1Size = X["bird1", "size"]
birdObs = X.points.copy(["bird1", "bird2"])
labels = X.features.copy("class")
duplicateObj = X.copy()
# Access an element by specifying a point and a feature
# Operates on whole points (seen as rows in image above)
# Operates on whole features (seen as columns in image above)
# Operates on points and features simultaneously (whole object)
Note: Nimble also supports representations of higher-dimensional data by allowing multi-dimensional objects to be embedded within points. For example, each point could contain a two-dimensional image.
nimble.data is the primary function for loading data from all accepted sources. It accepts raw python objects, strings that are paths to files or urls, and open file objects.
X = nimble.data([[1, 'a'], [2, 'b']])
X = nimble.data('/path/to/X.csv')
For convenience, nimble.ones, nimble.zeros, and nimble.identity are available to quickly create objects with specific data. The following create objects with 10 points and 10 features.
nimble.random.data is available to construct an object of random data with adjustable sparsity. The following creates a Matrix object with 10 points, 10 features and 0 sparsity.
randomData = nimble.random.data(10, 10, 0, returnType='Matrix')
Fetching returns the local path(s) to an online dataset, downloading and saving the data if necessary.
fileLocationsList = nimble.fetchFiles('UCI::iris')
Nimble data objects can be written to a file in a variety of formats. TrainedLearner objects can also be pickled.
Some information is set automatically on creation. By default automatic detection of returnType, pointNames, and featureNames occurs. Data object information can also be controlled by some of the parameters for nimble.data.
>>> X = nimble.data('/path/to/X.csv')
>>> X.shape # Always set
(3, 4)
>>> X.path # Set when source is a path
'/path/to/X.csv'
>>> X.getTypeString() # Automatically detected
'Matrix'
>>> X.features.getNames() # Automatically detected
['h', 'w', 'd']
>>> X.points.getNames() # Automatically detected
['0k1r3', '6t3n1', '8i7i3', '0k2r2']
>>> headers = ['height', 'width', 'depth']
>>> items = ['couch', 'table', 'chair', 'love seat']
>>> X = nimble.data('/path/to/dataset.csv',
... pointNames=items', featureNames=headers,
... returnType="DataFrame", name='furniture')
Once the object is created, the object's methods can be used to get or set information about the object.
Nimble provides several ways to print or stringify the data, with varying levels of flexibility.
# A representation of the data object that conforms to Python's repr standards
# A pretty-printed represenation of the data object
# Pretty-print the object with customized parameters
Nimble provides basic plotting functions using the matplotlib package on the backend.
X.plotFeatureAgainstFeature(x, y, ...)
X.plotFeatureAgainstFeatureRollingAverage(x, y, ...)
X.plotFeatureDistribution(feature, ...)
X.plotFeatureGroupMeans(feature, groupFeature, ...)
X.plotFeatureGroupStatistics(statistic, feature,
groupFeature, ...)
X.plotHeatMap(...)
X.[points/features].plot(identifiers, ...)
X.[points/features].plotMeans(identifiers, ...)
X.[points/features].plotStatistics(statistic,
identifiers, ...)
# A scatter plot showing feature x plotted against feature y
# A rolling average of one feature plotted against another feature
# Plot a histogram of the distribution of values in a feature
# Plot the means of a feature grouped by another feature
# Plot an aggregate statistic for each group of a feature
# Display a heat map of the data
# Bar chart comparing points/features
# Plot means with 95% confidence interval bars
# Bar chart comparing an aggregate statistic between points or
features
Iteration can occur over elements, points, or features.
>>> for element in X.iterateElements(order, only):
... print(element) # A single value
>>> for point in X.points:
... print(point) # A new Nimble data object containing the data from a single point
>>> for feature in X.features:
... print(feature) # A new Nimble data object containing the data from a single feature
Many methods provide information about the data within a Nimble data object. The following functions provide information or perform calculations on the data, but they do not modify the data in the object or return a new Nimble data object.
X.countElements(condition)
X.countUniqueElements(...)
X.containsZero()
X.report()
X.[points/features].count(condition)
X.[points/features].matching(function)
X.[points/features].similarities(function)
X.[points/features].statistics(function, ...)
X.features.report(basicStatistics,
extraStatisticFunctions)
# The number of elements satisfying the query
# Values and counts of unique elements
# True if any elements are equal to zero, otherwise False
# Information describing the contents of the object
# Number of points/features satisfying the query
# Identify points/features satisfying the query
# Similarity calculations on each point/feature
# Statistics calculations on each point/feature
# Removal of duplicate points/features
# Statistical information about each feature
Nimble uses INCLUSIVE indexes to support consistent behavior when using names or indices as identifiers.
Indexing can be performed from the data object or the points and features attributes.
For convenience, simple functions can be represented with strings. The strings must include a comparison operator (==, !=, >, <, >=, <=) or "is". An "is" (or "is not") must be followed by a nimble.match function or Python True, False, or None. See QueryString.
Element Query
numGreaterThan10 = X.countElements("> 10")
numNonMissing = X.countElements("is not missing")
Axis Query (using feature names from the example)
bigSpan = X.points.count("span > 30")
eagles = X.points.extract("class == eagle")
fast = X.points.copy("speed > 200")
Python operators can be used between a Nimble data object and a scalar or two Nimble data objects. The objects must be the same shape for elementwise operations and compatible shapes for matrix multiplication.
X + Y
X - Y
X * Y
X / Y
X ** Y
X % Y
X @ Y
# Elementwise Addition
# Elementwise Subtraction
# Elementwise Multiplication
# Elementwise Division
# Elementwise Power
# Elementwise Modulo
# Matrix Multiplication
Linear algebra functions can also be applied to Nimble data objects.
# (same as using @ operator)
# A square matrix raised to 'power' power
# The inverse of the matrix
# Find the solution to a linear system
# Returns the transposed object
Bound methods for easy access to simple statistics, returning values for each point or feature packed into a new object.
X.[points/features].max(order)
X.[points/features].mean(order)
X.[points/features].median(order)
X.[points/features].medianAbsoluteDeviation(order)
X.[points/features].min(order)
X.[points/features].mode(order)
X.[points/features].populationStandardDeviation(order)
X.[points/features].proportionMissing(order)
X.[points/features].proportionZero(order)
X.[points/features].quartiles(order)
X.[points/features].standardDeviation(order)
X.[points/features].uniqueCount(order)
# Maximum values along the calling axis.
# Mean values along the calling axis.
# Median values along the calling axis.
# Median absolute deviations along the calling axis.
# Minimum values along the calling axis.
# Modes along the calling axis.
# Population standard deviations along the calling axis.
# Proportions of values that are None or NaN along the calling axis.
# Proportions of values equal to zero along the calling axis.
# Quartiles along the calling axis
# Standard deviations along the calling axis.
# Numbers of unique values along the calling axis.
# Variances along the calling axis.
The listed methods may also be called directly from an object, which will calculate against ALL values in the data, and then return that as a number. Mostly useful for objects which are themselves a single point or single feature.
# Make a deep copy of the object, optionally as a different object type
# Copy the points/features meeting a given criteria
# Reorganize the points/features to be in a different order
# Sort the data based on point/feature values
† indicates an in-place operation that modifies the original data object rather than returning a copy
† X.replaceFeatureWithBinaryFeatures(featureToReplace)
† X.replaceRectangle(replaceWith, pointStart, featureStart, ...)
† X.transformElements(toTransform, ...)
X.calculateOnElements(toCalculate, ...)
† X.transformFeatureToIntegers(featureToConvert)
† X.[points/features].fillMatching(fillWith, matchingElements, ...)
† X.[points/features].replace(data, ...)
† X.[points/features].transform(function, ...)
X.[points/features].calculate(function, ...)
† X.features.normalize(function, ...)
# Replace a categorical feature with one-hot encoded features
# Replace a section of the data with other data
# Change elements to new values
# Apply a calculation to each element
# Map unique values to an integer and replace each element with the
integer value
# Replace elements in points/features with a different value(s)
# Replace points/features with a new points/features
# Modify the elements within points/features
# Apply a calculation to the elements within points/features
# Apply provided normalization function to features (optionally apply
same normalization to the features of a second object)
† indicates an in-place operation that modifies the original data object rather than returning a copy
† X.transpose()
† X.flatten(order, ...)
† X.unflatten(dataDimensions, order, ...)
X.groupByFeature(by, ...)
X.trainAndTestSets(testFraction, ...)
† X.[points/features].append(toAppend)
† X.[points/features].insert(insertBefore, toInsert, ...)
† X.[points/features].extract(toExtract, ...)
† X.[points/features].delete(toDelete, ...)
† X.[points/features].retain(toRetain, ...)
X.points.mapReduce(mapper, reducer)
# Invert the points and features of this object (inplace)
# Deconstruct this data into a single point
# Expand a one-dimensional object into a new shape
# Separate the data into groups based on the value in a single feature
# Separate the data into a training set and a testing set
# Add additional points/features to the end of the object
# Add additional points/features at a given index
# Remove points/features from the object and place them in a new object
# Remove points/features from the object
# Keep certain points/features of the object
# Apply a mapper and reducer function to each point/feature
# Make a repeated copies of the object
† indicates an in-place operation that modifies the original data object rather than returning a copy
nimble.calculate - Common calculation functions such as statistics and performance functions.
nimble.match - Common functions for determining if data satisfies a certain condition.
nimble.fill - Common functions for replacing missing data with another value.
nimble.random - Support for random data and randomness control within Nimble.
nimble.learners - Nimble's prebuilt custom learner algorithms.
nimble.exceptions - Nimble's custom exceptions types.
Nimble interfaces with popular machine learning packages, to apply their algorithms within our API. Interfaces are used by providing "package.learnerName". For example:
nimble.train("nimble.RidgeRegression", ...)
nimble.trainAndApply("sklearn.KNeighborsClassifier", ...)
nimble.trainAndTest("keras.Sequential", ...)
The interfaces and learners available to Nimble are dependent on the packages installed in the current environment.
Find the parameters and any default values for a learner.
nimble.learnerParameters(name)
nimble.showLearnerParameters(name)
# A list of parameters that the learner accepts
# Print parameters of the learner
# A dict of parameters to their default values
# Print the default values of the learner
The nimble.train function returns a TrainedLearner (referred to as "tl" below").
tl.learnerName
tl.arguments
tl.randomSeed
tl.tuning
tl.apply(testX, ...)
tl.getAttributes()
tl.getScores(testX, ...)
tl.incrementalTrain(trainX, trainY, ...)
tl.retrain(trainX, trainY, ...)
tl.save(outPath)
tl.test(performanceFunction,
testX, testY, ...)
# The name of learner used for training
# The arguments used for training
# The randomSeed applied for training
# Tuning object containing the
hyperparameter tuning results
# Apply the trained learner to new data
data
# Dictionary with attributes generated by the
learner
# The scores for all labels for each data point
# Continue to train with additional data
# Train the learner again on different data
# Save the learner for future use.
# Evaluate the accuracy of the learner on
testing data
The same API is available for any available learner.
trainedLearner = nimble.train(learnerName, trainX, trainY, ...)
predictedY = nimble.trainAndApply(learnerName, trainX, trainY, testX, ...)
performance = nimble.trainAndTest(learnerName, performanceFunction, trainX, trainY, testX, testY, ...)
performance = nimble.trainAndTestOnTrainingData(learnerName, performanceFunction, trainX, trainY, ...)
normalizedX = nimble.normalizeData(learnerName, trainX, ...)
filledX = nimble.fillMatching(learnerName, matchingElements, trainX, ...)
# Learn from the training data. Returns a TrainedLearner
# Make predictions on new data
# Evaluate the accuracy of the predictions on the testing data
# Evaluate the accuracy of the predictions on the used for training
# Transform the training (and optionally testing) data using the learnerName
specified normalization
# Replace matching elements in points/features with provided or calculated values
Arguments can be set in two ways: by using the arguments parameter in the nimble function or by passing the learner object's parameters as keyword arguments. Hyperparameter tuning is triggered by annotating the parameters in question with a nimble.Tune object. and by passing a nimble.Tuning object into training.
>>> tl = nimble.train("sklearn.KNeighborsClassifier', trainX, trainY, arguments={'n_neighbors': 7})
>>> tl = nimble.train("sklearn.KMeans', trainX, trainY, n_clusters=7)
>>> tuningObj = nimble.Tuning(validation=0.2, performanceFunction=rootMeanSquareError)
>>> tl = nimble.train("sklearn.Ridge', trainX, trainY, alpha=nimble.Tune([0.1, 1.0]), tuning=tuningObj)